
'Digital twins' can greatly benefit from being connected to each other, leading to increased efficiency, shared insights, saved time and reduced costs. Here, Senior Data Technologist Fionntán O'Donnell explores how models – the mathematical models at the heart of digital twins – can best be described and documented so they can more easily be shared.
----
Our research into digital twins – digital representations of physical assets – has been exploring the many ways to connect digital twins, from giving access to raw sensor data and querying APIs, to sharing visualisations and documenting high-level decisions. The idea of connecting digital twins together is at the core of the concept of the National Digital Twin, a federation of connected digital twins of the UK’s physical infrastructure.
In this blog post, I explore how models – the very heart of the function of digital twins – can be accessed and shared to increase the usefulness and public value of digital twins.
People use models to analyse, control, visualise and predict complex processes. Models are used in a range of domains including economics, public policy, the sciences, finance and urban planning.
In the context of engineering for the built environment, models can be used to: design and test the performance of physical assets before they’re created; monitor them once built; and continue to monitor them throughout their lifespan.
Digital twin data cycle
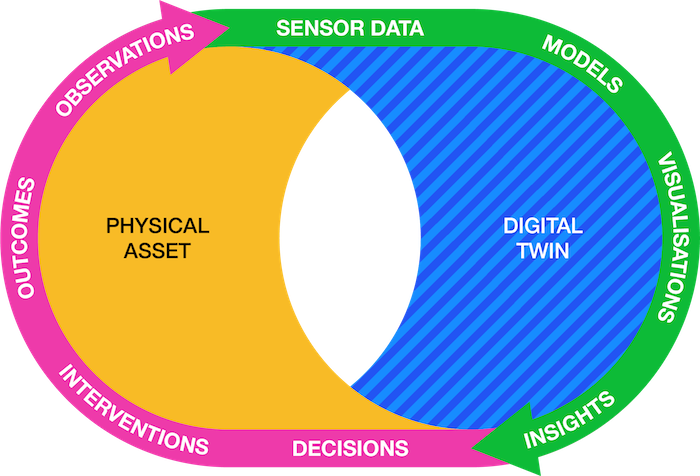
Documenting models
When sharing data it's good practice to provide documentation to help the user understand what it is, where it has come from and how it might be useful.
While sensor data, visualisations, insights, decisions, interventions and outcomes can be collected and documented as ‘standard’ data, models differ in a number of ways.
Perhaps most importantly, models can both contain and create information. They contain data such as networks, variables and parameters, which are key parts of a model’s architecture. Input data is usually passed through this architecture – creating output data which is then analysed. Models can be studied, picked apart and adapted to perform different tasks.
However, models in isolation are often not of much value. They need supporting documentation to help others understand how data passes through the model to help create insights.
Use cases for model documentation
Documentation is important for others who may wish to test or access these models for the purposes of:
- Validation – Validate the methods used and data created from others’ models. Reproducibility is an important part of the scientific method.
- Reuse with adaptation – Study and adapt parts of existing models to create a new model which performs its own distinct function.
- Reuse without adaptation – Instead of developing a model in-house, take an existing model created elsewhere which performs a similar function, without needing to understand its parts.
Working out how to cover all these different use cases when sharing models raises some interesting questions. Is there one correct way to document models? Is it necessary to first understand all of a model’s use cases before sharing? At what point is the documentation considered complete?
To answer these questions there is a need for best-practice guidance and standards around what documentation to include with models.
Metadata for digital twin models
Metadata is data that describes other data. It allows others to understand the content and structure of a dataset, and in this case, a model, making it easier to find and use.
Creating precise standards for this takes much time, discussion and agreement across a collaborative community.
However, to start thinking about the problem, below is a list of some metadata that could be included with a model. This list is not designed to be definitive but more a conversation starter about how digital twin models could be documented.
When compiling this list, we thought about the metadata we see and use most commonly. What metadata is the most helpful? What could be added? What shouldn’t be there? In what ways does model metadata differ from regular metadata?
Suggested digital twin model metadata list
Supporting documentation
- How was the model created? Was there a research paper or report written about creating the model? Is that available?
- Is the code used to create the model available? Does the code use good coding conventions with informative comments?
- Who are the authors/organisation/team who created or released the model?
- Who is in charge of this shared model? What is the governance around it
- Licence – is this model free to use? Can it be used commercially?
Technical information
- What is the model’s filetype and size?
- Is a diagram available of the architecture of model showing the passage of data?
- What is the format of the input data? What datatypes does the model accept?
- What is the format of the output data?
- Where and how can the model be accessed?
- What steps are needed to run and test the model?
- What were the parameters used to generate the available version of the model?
- What is the programming language used to create the model? Is running the model dependent on this language?
- What hardware was used to create the model? How much computing power is needed?
- What are the model creation and release dates?
- What is the version of the model? Are other versions available?
Data description
- Where can the data used to create the model be found?
- What does the dataset contain? Is this well documented?
- Which physical twin or sensors generated the data?
- What are the ethical, legal and social contexts in which the data was gathered?
Models beyond humans
It’s also worth thinking about how to make this information machine readable. Assuming a standard for model documentation was widely adopted – a machine-readable format would help enhance accessibility, findability and usability.
What could be done with the model equivalent of the open data portal provided by gov.uk or Google’s dataset search? Could we create something like the Data Catalog Vocabulary standard for digital twin models?
DAFNI
Interestingly, a model documentation standard has been developed by the people behind Data & Analytics Facility for National Infrastructure (DAFNI), a platform that allows engineering researchers to share and run data, models and workflows.
Speaking at the DAFNI showcase event, Nick Cook, Senior Analyst at Tessella, explained how all model metadata within DAFNI is based on a standard: the National Infrastructure Model Definition. Every model has an attached file which contains a basic description and other information, eg the variables the model takes. This helps the DAFNI system run the models within automated workflows. The DAFNI team are hoping this becomes a national and international standard.
It remains to be seen whether the digital twin community ever settles on this one standard to document models, or opts for multiple standards. In the meantime, simple guidance and good practice should be promoted so that others, whether in large projects or small, can continue to push the model-sharing space forward.
Get in touch
Are you interested in how models are shared? Do you have insights about sharing models beyond the domain of digital twins? Have we missed any important new developments in this area? Then get in touch. It’d be great to hear from you.