
Increasing access to data about people while retaining trust and protecting privacy is one of the most important challenges data practitioners face today. Techniques such as anonymisation and synthetic data may be useful for this, but they remain the playground of a few experts.
In this blogpost Head of Technology Olivier Thereaux showcases the ODI’s recent work to create resources to better manage the risk of re-identification.
Increasing access to data can unlock more value for our societies and economies. This is one of the core principles of the ODI’s mission to create an open, trustworthy data ecosystem. Increased access to data can foster innovation, enable better services and even save lives.
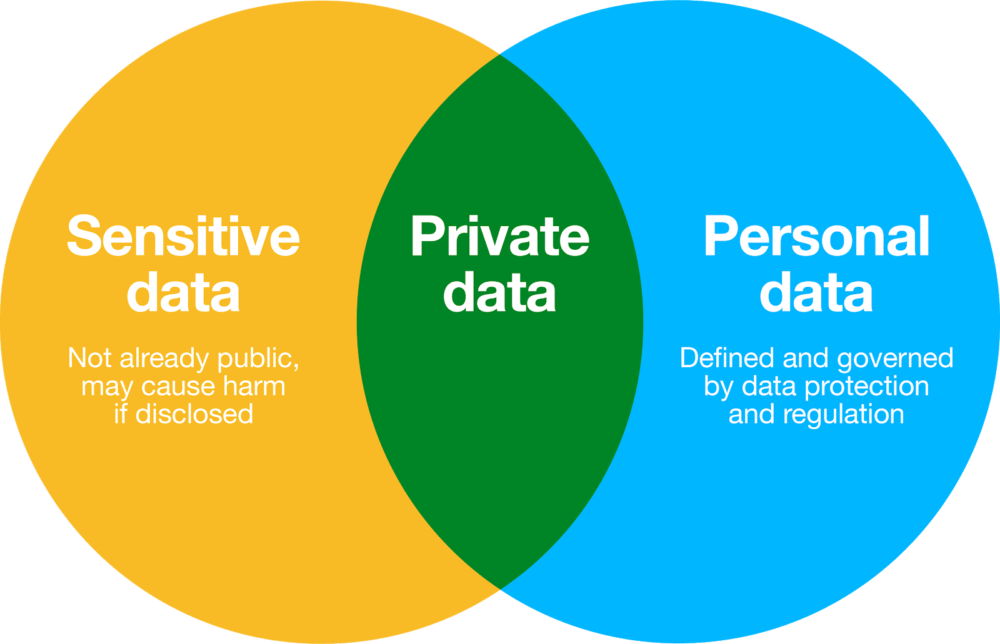
There are however many good reasons why data should not be released openly or even shared. This is the case for sensitive data, a category which includes: the kind of personal data deemed ‘special’ by recent regulation; the kind of corporate or state secrets which could create significant harm if revealed; or even information about the whereabouts of members of endangered species.
Creating value from sensitive data
Tools and techniques exist which enable the creation of value from sensitive data while safeguarding privacy and helping ‘data stewards’ (organisation or person who collects, maintains and shares data) be more responsible and to maintain trust. As part of our UK government-funded research and development programme, we have been looking at two of those techniques: anonymisation, and synthetic data.
Back in November 2018, we were writing about the fact that anonymisation did not seem to be broadly known or understood. While the literature review collated for us by Eticas Research showed us that there is a solid legal and academic understanding of anonymisation, our research on how organisations perceive personal data and the risk of re-identification highlighted that there is a broad range of understanding around the definition of personal data, and how anonymisation can help unlock its value.
Managing the risk of re-identification
Our early research highlighted three specific challenges:
- Firstly, many data practitioners have a wrong (but understandable) perception that open data never includes personal information.
- Secondly, most guidance on anonymisation assumes that the people who use the data and what they use it for are well known in advance – something inherently hard to do with open data.
- Finally, the Anonymisation Case Studies document prepared for us by Eticas demonstrates that there are more famous examples of anonymisation gone wrong than examples of where it has been done right.
We set out to explore these challenges, resulting in our report: Anonymisation and open data: An introduction to managing the risk of re-identification. This short document – written for data practitioners who do not necessarily have prior knowledge of anonymisation – provides evidence of personal and anonymised data in contemporary open data (more common than you would think!) and introduces key concepts such as the risk of re-identification, utility of data after anonymisation, and the trade-off between the two. It also introduces in non-technical terms a variety of anonymisation techniques, and closes on a look at how new technologies may further push the boundaries of the discipline.
Synthetic data
One of those promising technologies is synthetic data – data that is created by an automated process such that it holds similar statistical patterns as an original dataset. Intuitively, it is easy to see how this could enable the sharing or open release of data similar to very sensitive data, but with much less risk attached to it. A project organised by ODI Leeds and NHS England looking into synthetic data about A&E admissions gave us the perfect opportunity to contribute and gather practical experience of synthetic data.
Data about emergency admissions has the potential to create insights that make emergency services better, faster, cheaper, and save lives in the process. But this data is extraordinarily sensitive, as it relates to people at their most vulnerable, and it therefore is only shared in anonymised form, under strict sharing agreement. Without equitable access, the ability to generate life-saving insights decreases dramatically. Creating and publishing synthetic data might help amateurs and professionals alike create models and tools safely, with future potential to be applied on the actual data.
Our contribution to this project was two-fold. First, we explored using a number of ODI practical tools such as Data Ecosystem Mapping to draw a threat model for this synthetic data – creating a variety of scenarios of what could possibly go wrong by looking at all the actors in the ecosystem of data and value around this data. We presented our findings in Leeds at a workshop organised by ODI Leeds, and used the experience when creating a prototype companion to the Anonymisation Decision-Making Framework, the comprehensive guide produced by the UK Anonymisation Network. The prototype is still a work in progress – we will be iterating it and will publish it soon.
Finally, we also created a tutorial on synthetic data. Aimed at developers and the more code-savvy data practitioners, the tutorial walks you through some of the steps followed in the synthetic A&E data project.
Making data processing and sharing more trustworthy
Through this research, we did confirm that anonymisation and synthetic data are among the tools and techniques with potential to make data processing and sharing more trustworthy, by protecting data subjects from re-identification and other harmful incidents. Our work also uncovered a very significant gap in knowledge and understanding between a small group of experts thinking about cutting-edge techniques, and the majority of data practitioners, often confused about best practices around personal data.
We hope the resources created through this project will help create a stronger data ecosystem, where data about people can be used in ways that are safe and trustworthy.
If you wish to build on this work, the register of actors started through this project may be a good starting point – and we could use suggestions of more organisations around the world who can help with anonymisation.
And please get in touch if you have a success story to share about making data more open while managing the risk of re-identification.