
This article was written by 2022 ODI fellow Sameer Mehta, with Milind Dawande, Mike Redeker Distinguished Professor, University of Texas and Liying Mu, Assistant Professor, University of Delaware; and was originally published on the World Economic Forum website. It has been reposted here in accordance with the WEF license.
- As an organizational form, data cooperatives empower individuals by giving them control over the data they share and by effectively monetizing the data.
- The effective allocation of a data cooperative’s revenue among its members, while challenging, is paramount for the scale up and sustenance of the cooperative.
- Robin-Hood-style revenue-allocation schemes that compensate the ‘privacy poor’ at the expense of the ‘privacy rich’ are effective.
In the Davos Agenda 2022, leaders of the world such as Xi Jinping acknowledged that: “We need to make generally acceptable rules for the digital economy that will create an open, just, and non-discriminatory environment for scientific and technological innovation.”
The availability of massive amounts of consumer data – an inescapable consequence of the digital economy – along with the rapid development of methods to exploit it for intelligent business decisions, has spurred innovation not only in the way firms conduct business but also in the way data is collected. The past few years have witnessed a growing interest in bottom-up data institutions such as data cooperatives, which collect voluntarily shared data by individual members and monetize the pooled data to benefit the entire member community.
New data cooperatives empower individuals through control over their data
Thanks to rapid technological advances and regulations that uphold the data rights of individuals, a number of new data cooperatives have sprung up: Driver’s Seat, for instance, is a driver-owned cooperative that aggregates work-related data from the smartphones of gig-economy drivers, Resonate is a cooperative owned by musicians and their patrons, and Swash aggregates web-surfing data of individuals. The emergence of such cooperatives has the potential to address various socioeconomic and environmental issues.
As an organizational form, data cooperatives empower individuals by giving them complete control over the quality and quantity of the data they share. Via such controls, data cooperative not only establish an ecosystem of trust but also complement the recent data-protection laws such as the GDPR in the European Union and the CCPA in the United States. Moreover, by aggregating individual data, a cooperative improves its bargaining power and can thereby command a better price for the pooled data. Whereas the idea of forming data cooperatives is promising, they have not scaled up at a desirable pace.
Designing effective revenue-allocation schemes remains a challenge
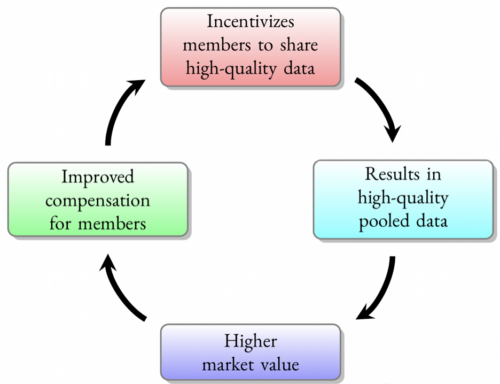
A revenue-allocation scheme determines how the monetized revenue should be distributed among the members of the cooperative. Implementing an effective scheme is central to its sustenance, as it generates a beneficial virtuous cycle. It creates incentives for members to share high quality data, which in turn results in high quality aggregate data – this increases the market value of the pooled data and hence the cooperative’s revenue, ultimately resulting in improved compensation for members.
To design an effective revenue-allocation scheme, cooperatives need to account for the data contributions – which depend on both the quality and quantity of the shared data – of individual members. Also important are the economic incentives of the members to participate and share high quality and useful data. On the flip side, the incentives of the members to share data, in turn, depend on the revenue-allocation scheme employed by the cooperative. If the compensation provided by a scheme is deemed unattractive by members, then they will naturally refrain from sharing data. Furthermore, for a cooperative to be sustainable, a desirable property of an allocation scheme is that it should not create perverse incentives for members to break away and form smaller groups. Not surprisingly, present day cooperatives acknowledge the design of such schemes to be challenging.
Revenue-allocation schemes need Robin-Hood-style adjustments
In a recent study, we develop and analyze the efficacy of various easy-to-implement revenue-allocation schemes. Two main insights emerge:
An intuitive and natural scheme is to distribute the cooperative’s total revenue to its members in proportion to their individual data contribution. While such a scheme is appealing and seemingly fair, it is not always effective, because it fails to, firstly, account for the members’ sensitivity to share their data, and, secondly, provide sufficient incentives for members who have a relatively high sensitivity to privacy.
The design of an effective scheme necessitates Robin-Hood-style adjustments in the compensation to the members; that is, the scheme must provide preferential treatment to “privacy-poor” members, as those who are highly privacy-sensitive, at the expense of “privacy-rich” members. Such a treatment cannot be too lopsided, however, for it can be taxing to the extent that the privacy-rich members choose to break away from the cooperative. Thus, effective schemes must walk a tightrope in providing just the right amount of additional incentive for privacy-sensitivity while ensuring that the flock of members stays together.
As an institution, data cooperatives are attractive in that they offer fresh consumer data obtained in an open, non-discriminatory, and privacy respecting manner after duly compensating members. An attractive revenue-allocation scheme is the backbone of a thriving data cooperative and key to helping it realize its full potential. Such cooperatives not only empower individuals by monetizing their data, but also have the potential to shape the data markets of the future.
The authors would like to thank the Open Data Institute for facilitating access to data cooperatives, practitioners, and policy makers.