
Tools that enable collaboration with data can help engage communities, reduce efforts in data management and create useful and high-quality datasets that can be used across sectors and domains. This study investigates the challenges that people face when working together on data tasks, and explores how current information systems and tools support them in their work By Laura Koesten
This article summarises a paper, authored by Laura Koesten, Emilia Kacprzak, Jeni Tennison, Elena Simperl, which was presented at CHI’19, the ACM CHI Conference on Human Factors in Computing Systems in, this weekend in Glasgow
More and more people are working with structured data every day. By structured data we mean data that is organised as spreadsheets, tables or databases. However, having data available does not always mean it can be used purposefully.
Tools that enable collaboration with data can help engage communities, reduce efforts in data management and create useful and high-quality datasets that can be used across sectors and domains.
We describe a study in which we investigate the challenges that people face when working together on data tasks, and explore how current information systems and tools support them in their work. Data projects are often carried out in teams, drawing on skills from several areas, including domain knowledge, statistics, data engineering and interaction design. We wanted to understand the specific user needs in collaboration with data and how they are supported by current technology.
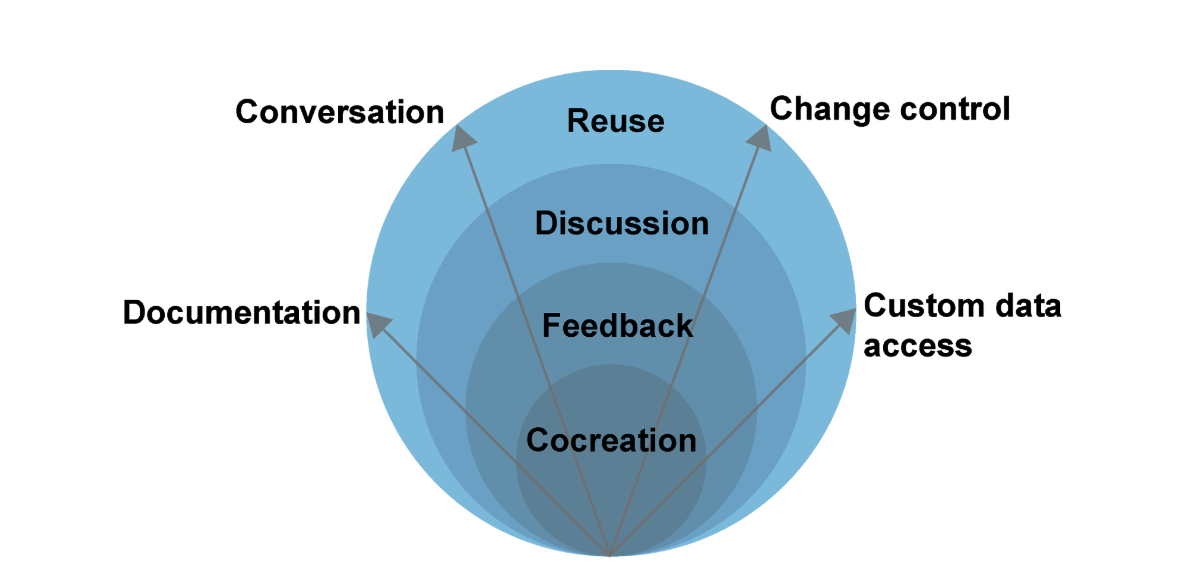
‘Collaboration with data’ can be seen on a spectrum that spans across a wide range of scenarios: from creating, processing or analysing data in an interdisciplinary team to sharing data with others and receiving feedback or discussing it. It’s also includes the reuse of someone else’s data in a new context, with little to no interaction with the data producer.
Collaboration may involve anything from a small group of people sharing an office to large distributed teams to open communities where people join all the time.
Based on a qualitative study we derive four main high-level user needs that tools that help us work with data would benefit from:
- Documentation of data and its lifecycle
- Conversation
- Change control
- Custom data access
We compared these against the capabilities of twenty systems that are commonly associated with data activities, including data publishing software, wikis, web-based collaboration tools, and online community platforms. These are tools that people use to work with data; to either co-create, edit, publish, share or reuse it.
Structured documentation of data and its lifecycle
This includes the scope, forms and granularity of documentation, such as metadata, annotations and text descriptions. Documentation needs to focus not just on interoperability, but on being understandable by people.
Users would benefit from a better understanding of a dataset’s lifecycle, including its purpose and methodology. How a dataset came to be influences what it can be used for and we should create more formalised or automatic ways to capture this information. The culture of documenting methodology in a more or less structured way exists for instance in scientific papers or to some extent for code; we need to adapt similar practices for datasets more widely.
Conversation
As we cannot document everything for every possible use case there will always be a need among collaborators to communicate to allow a shared understanding of the data and understand attached limitations or caveats.There are various ways to support this through tool design; this includes advanced support for different types of conversations, e.g. through comments and other feedback channels. Functionalities to post data snippets in communication channels and being able to refer comments to exact subsets of data was one example mentioned by our participants.
Change control
The ability to access earlier versions has long been recognised in tools that allow us to work together with text or code. This includes, for example, being able to revert to a version before particular cleaning methods have been applied or notification services when a collaborator makes a change in the dataset, or when an updated version of a dataset is published. We believe version control really tailored to datasets needs to track changes on different levels of the dataset, such as rows, columns, or individual cells. Designing for transparency would further include displaying the provenance and, where possible, capture the purpose of these changes.
Custom data access
People are collaborating with data in different contexts and therefore need different data formats and representations. Anyone can benefit from tools allowing input mechanisms on different levels to support different levels of data literacy and technical skills. Being able to easily plot data, access subsets of data or create relations between tables allows a shared understanding between collaborators.
While we found each of these needs partially or fully supported in some of the tools, we believe there is a huge space for research and development of a more seamless and intuitive tools landscape when it comes to data-centric work tasks. None of the tools supported all of these needs while being able to support the whole spectrum of data-centric activities. While that might not be necessary, what we are interested in is reducing the barriers and pain points for people working together with data.
The findings of this work help us formalise practices around data teamwork, and build a better understanding how people’s motivations and barriers when working with structured data. Research exploring conversations and collaborative work practices with data can further be used for the development of user-centred and transparent reporting practices for data sharing and reuse.
We think there is a gap in research that looks at how existing methods and tools that are used to collaborate in documents, or with code, could be applied to collaboration with data.
But at the same time, we believe that working with data comes with unique challenges and needs – as data is on the one hand so structured, but on the other hand so mutable.