Data on the web comes in several modes, for example:
- files that you can download
- APIs
- content such as HTML tables
- custom data browsers
- and more.
Analysing or using data without software is incredibly cumbersome if not impossible. Here we show you how you can import data from the web into a tool called R. Reasons why R has become so popular, and continues to grow, are that it’s free, open source, with state-of-the-art practices and a fantastic community.
R, and its IDE RStudio, is a statistical software and data analysis environment. You can find a quick interactive tutorial on Code School or well-designed courses on DataCamp. If you haven’t installed R, you can paste and try the code at R-fiddle.
Comma separated values (CSV)
Reading a CSV-file from an URL could not be simpler. Here are the number of police officers in Scotland over time.
<pre><code>read.csv("http://www.quandl.com/api/v1/datasets/EUROSTAT/CRIM_PLCE_42.csv") </code></pre>
And yet it is not guaranteed that this works. Why? Many CSVs don’t follow a minimal standard. For example, the first row of a CSV file should be a header row, but some data has a header row in a later line. We use the skip option.
<pre><code>read.csv("http://www.royalwolverhamptonhospitals.nhs.uk/files/mth%206%20september%202013%20(3).csv", skip = 2) </code></pre>
Unfortunately, read.csv() does not cope well with SSL, that is https connections. An alternative employs download.file, see below.
<pre><code># Fail read.csv("https://raw.github.com/sciruela/Happiness-Salaries/master/data.csv") # Win read.url <- function(url, ...){ tmpFile <- tempfile() download.file(url, destfile = tmpFile, method = "curl") url.data <- read.csv(tmpFile, ...) return(url.data) } read.url("https://raw.github.com/sciruela/Happiness-Salaries/master/data.csv") </code></pre>
What gifts did David Cameron receive in May-June 2013?
The UK government publishes data about gifts David Cameron receives and what happens with them. We will use it as another example.
The data is behind a secure connection, so we use our read.url function. Yet it still produces an error. The reason is a £ symbol in the header row.
<pre><code>read.url("https://www.gov.uk/government/uploads/system/uploads/attachment_data/file/246663/pmgiftsreceivedaprjun13.csv") </code></pre>
A faster and more flexible tool is fread from the data.table package (see the documentation).
<pre><code>install.packages("data.table") library(data.table) read.url <- function(url, ...){ tmpFile <- tempfile() download.file(url, destfile = tmpFile, method = "curl") url.data <- fread(tmpFile, ...) return(url.data) } read.url("https://www.gov.uk/government/uploads/system/uploads/attachment_data/file/246663/pmgiftsreceivedaprjun13.csv") </code></pre>
And the results are:
| Date received | From | Gift | Value | Outcome |
|---|---|---|---|---|
| May-13 | President of UAE | Model boat | Over limit | Held by Department |
| Jun-13 | Tony Pontone, Albemarle | Gallery Art work | Over limit | Held by Department |
| Jun-13 | President of the United States | Jewellery | Over limit | Held by Department |
| Jun-13 | President of Pakistan | Rug | Over limit | Held by Department |
| Jun-13 | President of Kazakhstan | Medals & stamp album | Over limit | Held by Department |
A useful trick is to only read a few lines. This makes especially sense when you have a large dataset like the Land Registry’s Price Paid Data (several GB in its complete form).
<pre><code>read.csv("http://publicdata.landregistry.gov.uk/market-trend-data/price-paid-data/a/pp-complete.csv", nrow = 10) </code></pre>
APIs
R’s community has built wrapper packages for many APIs. For example, the World Bank Development indicators are available in R. A quick example with Google’s Ngram Viewer is below.
What is more popular: line charts or line graphs?
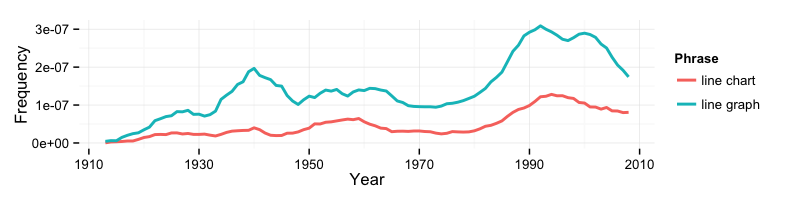
<pre><code># Install the package install.packages(c("ngramr", "ggplot2")) # Load it into R library(ngramr) library(ggplot2) # Case-insensitive search lines <- ngrami(c("line chart", "line graph"), year_start = 1913) ggplot(lines, aes(Year, Frequency, colour = Phrase)) + theme_minimal() + geom_line(lwd = 1) </code></pre>
ROpenSci collected an extensive list of R packages that deal with APIs. It includes Twitter, the Guardian, Amazon Mechanical Turk and many more.
Scraping
Scraping is an art in itself and is perhaps best left in the hands of experts such as our friends at ScraperWiki. However, R has support (packages, no surprise here) for popular tools. Worth mentioning is RCurl and XML.
Xiao Nan made a useful table of the R scraping toolkit.
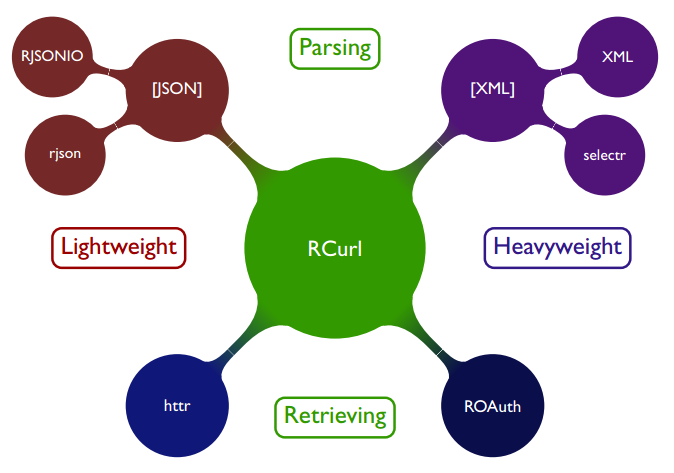
Source: Xiao Nan, @road2stat
Lastly, I wished that I’d have known about parallelisation options earlier… For example, getURIAsynchronous from RCurl.
I also wrote a tutorial on how to import a HTML table into R.
What to do next
Using a tool like R has another great advantage: unlike manually downloading a file, you can easily re-use and share your work. Having some R code instead of an Excel file means your analysis is reproducible and you may be able to adapt it for future projects or if an updated dataset was released.
If you need help you can find support via stackoverflow and the R-help mailing list. If you’re looking for data, browse a catalogue (e.g. data.gov.uk), use a web search engine or ask me on Twitter.