
Is it possible to measure the value of data? Many now recognise how important data is, but how it should be governed and regulated is often confused by a lack of consensus on how it can be valued
By Ben Snaith, in collaboration with Peter Wells and Anna Scott
The ODI has a longstanding interest in the challenge of how to value data, alongside our mission to build an open, trustworthy data ecosystem.
On 18 July, we held a workshop – gathering people from national and multinational public sector organisations, academia, big businesses, startups, philanthropic funders and venture capitalists – to explore this hotly debated subject. The workshop was hosted by the ODI CEO Jeni Tennison and Diane Coyle from the Bennett Institute for Public Policy. Attendees included entrepreneur and writer/curator of the Exponential View newsletter Azeem Azhar; Jonathan Haskel from Imperial College Business School – who recently co-wrote a book on the intangible economy; and Will Page, Director of Economics at Spotify.
Stifled innovation and unaddressed problems for citizens
Trust in data itself has been undermined by recent global events. In light of the changing landscape, there has been debate around how to protect citizens from data exploitation, while continuing to get value from data. This dilemma can affect everything from whether there is a list of postal addresses in a country, freely available for people and companies to use and innovate with, to how we respond to situations such as the recent Facebook/Cambridge Analytica scandal.
Until society makes more progress in learning how to value data, then innovation will continue to be stilted and problems that affect citizens and consumers will remain unaddressed.
Without knowing how to determine the value of data, how can we expect it be fairly distributed?
A 2017 report on the transport sector, produced by the ODI and Deloitte, illustrates why data sharing is so important. It states that an estimated £15bn is not being realised due to three main reasons: siloed thinking; a fear of breaching privacy, security and safety; and a belief that the costs of sharing data outweigh benefits. A belief that would be easier to challenge if we had a better understanding of how to value data.
The recent Wendy Hall and Jérôme Presenti independent review of AI for the UK government calls for data trusts, meant here as proven and trusted frameworks and agreements, to ensure that data exchanges are “secure and mutually beneficial” for all stakeholders – including organisations and citizens. The UK government is already acting upon this recommendation, but without knowing how to determine the value of data, how can we expect it to be fairly distributed?
We convened the workshop to enable people to share their perspectives on the value of data and the policy implications, and address open research questions. We hoped the discussions and insights would also inform current research at the ODI and the Bennett Institute, and identify research questions for future work. We discussed various timely issues, from the changing business landscape to data’s use determining its value.
The most valuable companies now rely on data
The six most valuable companies in the world are now technology companies that rely upon data, while the companies dislodged at the top are now attempting to catch up and will need data to do that.
Data networks and the AI lock-in-loop are affecting market competition by creating new barriers to entry. These two effects are inherently linked; the data network effect is when a product becomes smarter the more it is used and the more data it receives from users. The AI lock-in-loop is the idea that this better product will then attract more users and therefore keep exploiting the network effects to improve. The loop will continue and make it increasingly difficult for new entrants to join the market.
The firms who were able to first capitalise on these effects – such as Uber, Netflix and Facebook – are now in strong market positions.
While older algorithmic approaches tend to reach a performance limit (at which point adding more data is futile), newer AI methods – such as deep learning and neural networks – seem to continue to improve, no matter the volume of data added (as shown in the diagram below). This is one of the factors driving the push for increased data collection and will continue to affect which data will be seen as most valuable, likely to be the data most useful for deep learning.
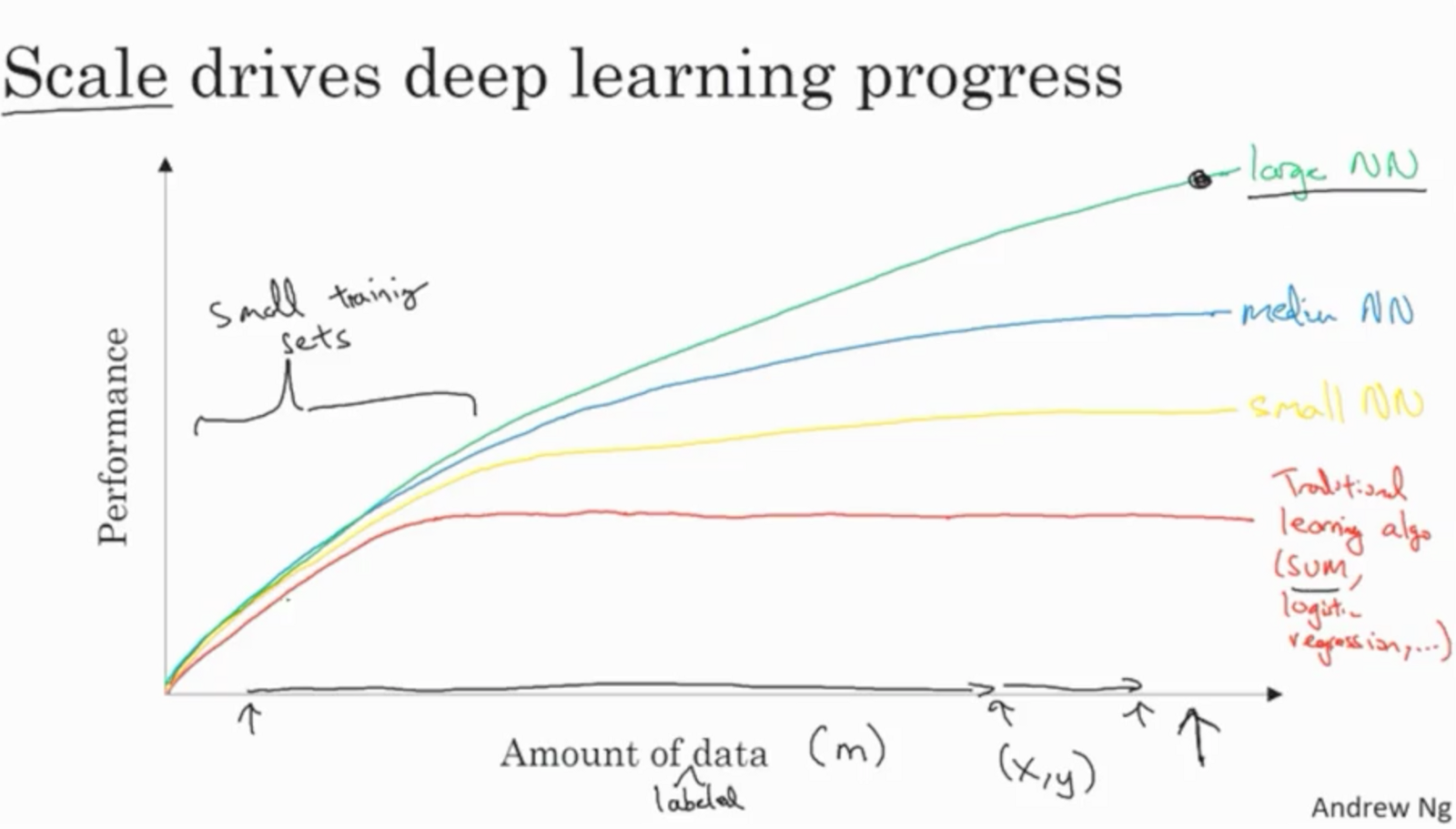
Image: Andrew Ng, from a post on lessons learned from his deep learning course
Data’s value is more than the sum of its parts
There are many issues with the oft-made adage that ‘data is the new oil’. The two differ in many characteristics; data is superabundant compared to the finite oil supply and is non-rivalrous in nature.
Data, as an intangible asset, is characterised by externalities or spillovers, whereby its production or consumption benefits or harms third parties. Managed well – and in a way that reduces harm – data can be an important public good, which can help businesses to innovate and grow. Data is more valuable when it is used than when simply hoarded.
There is a paradox to be resolved that is central to the issue of valuing data. A single piece of data only becomes useful – and therefore valuable – once combined with other data. The Strava heatmap demonstrates this. Individual fitness routes don’t tell us much apart from an individual’s habits, but when every Strava users’ routes are combined we can learn a great deal about the popularity of certain areas and general trends across a population. This is valuable to local communities who can better support running infrastructure and planning, but the map could also be used to identify secret military bases across the world. Hence, with the power of stewarding large datasets comes great responsibility.
But if data cannot be valued as the sum of its parts – how can it be valued? Some have suggested that data marketplaces, such as Ocean Protocol, will be key to addressing this challenge.
But not every country has a market economy; different countries place different emphases on the competing rights of individuals, companies, communities and governments to data.
Governments and businesses will use the same data for different purposes. To put it another way, they have different desired outcomes, economic systems and social contracts. The Chinese government's mechanisms to value data seem different to the USA and to European nations. As China's influence grows will this have an effect have on how other countries value data?
The overall benefits of treating data as infrastructure are increasingly felt. Firms that invest in improving their data infrastructure will gain a competitive advantage as the next generation of public and private services increasingly rely upon data.
Jonathan Haskell's previous work helps us to understand how to quantify the value of data to the economy by counting up the costs it incurs. Yet it is much more difficult to quantify the effect on GDP of investment in data than it is to quantify investment in more tangible assets, such as machinery – this is yet more value that is not fully captured. Similarly, Diane Coyle had previously concluded that current GDP estimates were failing to include the full extent of digital activities, or measure the further value when data is resold or reused. Moving forward new methods will have to be adopted to get a truer estimate of the value of data.
The shifting value of consumer data: from CDs to Spotify
Spotify's new dashboard for musicians lets them view data, such as their listening figures, number of followers, the age, gender and location of their listeners and much more. This has value for the artist, who can alter their behaviour to make better decisions – such as when to tour, who to collaborate with and when to release new music. This was data that was previously either uncollected or held closely within music companies, now it can create more value. This data is only available to the artists, and not to the public, therefore its value is difficult to calculate.
The methods of measuring the value of the music sector have also changed. When music was listened to through CDs, cassettes and vinyl, analysis could inform us who was buying what album at which store, but little more. The analysis of streaming data offers the opportunity to get a much richer understanding of how music is being consumed. A 2012 study found that the UK music industry was worth £3.2bn more than previously thought. But there are still challenges in how comparisons between online and physical consumption are made and how to best use this new source of data.
We must collaborate to find new methods of measuring data’s value
Society is just at the start of realising the full potential of data to society and to the economy – driving this will be vastly increasing volumes of data being collected, stored and used. It is, therefore, increasingly important to find a way to measure data’s full value, as it is clear that our current methods are insufficient.
For this change to happen, we need to work collaboratively and push for engagement between people with different expertise – this is an issue that needs to be addressed by policymakers, economists, technologists, business and wider civil society.
Jeni and Diane will be developing a research agenda to explore the ideas raised further, with a particular focus on the measurement and regulatory aspects of valuing data.
If you want to discuss this topic more please let us know at [email protected].