
While the AI data ecosystem is growing, with tens of thousands of datasets published weekly on repositories like TensorFlow, HuggingFace, OpenML, Kaggle, and Dataverse, little is known about the governance of this data. Part of the issue is due to the level of manual effort required to implement responsible AI practices across the ecosystem, which can particularly disadvantage smaller organisations. At the same time, public AI data infrastructure is only slowly adopting open standards which have proved their value in other contexts, from science to government to the entire web.
What is Croissant?
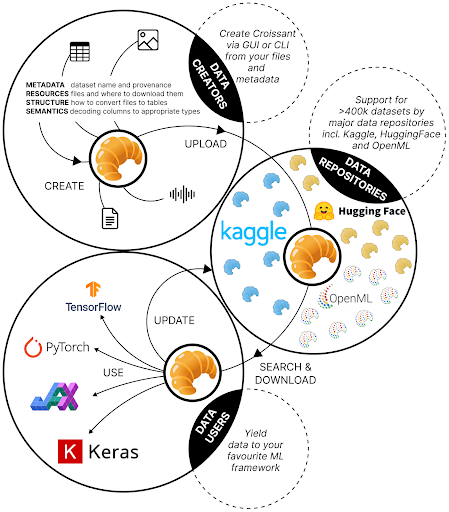
Enter Croissant, an emerging community standard, that provides machine-readable metadata for ML datasets, enhancing their accessibility, discoverability, and reproducibility while complementing their data cards or other documentation formats. Supported by major platforms like those mentioned above, and championed by the ODI, Croissant is set to play a pivotal role in ensuring robust data management and accountability in the evolving landscape of data-centric AI.
Recent insights from our analysis of AI data governance have underscored the critical need for improved data-centric frameworks in AI development. Particularly pressing are the issues surrounding the governance of data access and management of downstream tasks – areas that lack robust, standardised practices, thereby posing significant challenges to the ethical and effective deployment of AI/ML systems.
The effective governance of datasets is crucial, particularly concerning the maintenance of datasets. Similar to how Wikipedia relies on a community of editors to continuously update and improve its content, datasets used for AI training must also be regularly maintained and updated to reflect changes in the real world. If not kept up, data drift in machine learning models can lead to degraded performance over time as the real-world data distribution shifts from the training data. For instance, in computer vision systems for retail stores, models trained to identify objects may degrade over time as new products are introduced, store layouts change and lighting conditions fluctuate. This drift in the data distribution can cause the model to make incorrect predictions. Therefore, continuously monitoring and updating training data is crucial to maintain model accuracy.
Why do we need standards?
Data access governance refers to the policies, processes, and standards determining how data can be accessed, who can access it, and under what conditions. Our insights reveal a pronounced scarcity of information on AI data access governance: many AI projects lack structured practices for managing data throughout its lifecycle, particularly during model evaluation and fine-tuning. This information gap creates inconsistencies and potential ethical risks as there are often no clear guidelines on who can access AI/ML data, how it should be handled, and the best practices for maintaining data integrity and security.
For example, a healthcare organisation developing an AI system for disease diagnosis may lack clear protocols for managing patient data used to train the model. Data scientists might have unrestricted access to sensitive medical records during preprocessing, raising privacy concerns. Conversely, clinicians involved in model evaluation might not have access to the necessary annotated data, hindering their ability to validate the model’s performance.
This overall lack of transparency and governance within the ecosystem necessitates community-driven solutions like Croissant to ensure high standards of data management and accountability. Croissant combines typical metadata with data structure details and ML-specific information into a single machine-readable file for any dataset, in doing so not only providing a rich description of the dataset but also supporting efficient access by providing this information for its practical use in ML projects.
This documentation is applicable across contexts such as in the field of responsible AI (RAI). The Croissant vocabulary has an optional extension (‘Croissant-RAI’) that allows the recording of datasets’ collection and processing methods, sampling decisions, use cases, and limitations. This in-depth information on a dataset’s provenance and lineage is useful when assessing what that dataset is to be used for; in the aforementioned example of a healthcare organisation, Croissant-RAI annotation can inform clinicians as they evaluate a model’s training data and its suitability.
Likewise, in the case of participatory data, where some ML datasets are created as a result of a large-scale collaborative effort, Croissant metadata can provide a single point of reference for a user to understand the participatory element of a dataset’s creation and highlight potential biases and limitations that could arise within the dataset as a result.
How to use Croissant
Each of the 400k+ datasets that have attached Croissant metadata can be easily loaded into typical ML frameworks and toolkits, streamlining their usage and shareability. Recently, TensorFlow and HuggingFace have both expanded their application programme interfaces (APIs) to support Croissant, demonstrating their commitment to the building of data access governance practices. Croissant is also accessible to individual users. If someone is looking to publish their dataset with the Croissant format, they can use the ‘Croissant editor’, which allows them to easily inspect, create, or modify Croissant descriptions for their datasets.
Get involved
The ODI has been an early supporter of the initiative, with Professor Elena Simperl, the Director of Research, being co-chair of the Croissant working group at MLCommons. As the consortium continues to iterate on the design and implementation of Croissant, new members are always welcome. You can join the working group here.


